These days, keeping up with GenAI models is like playing Whac-A-Mole in a lab coat – every week, a new “revolution” pops up, winking at you with promises of genius. Recently, I gained access to Manus AI, a much-hyped tool developed by the Chinese startup Monica, and decided to put it to the ultimate test. To provide meaningful context and comparison, I simultaneously evaluated it against three of the most powerful and widely recognized AI models available today: OpenAI’s ChatGPT-o1, Google’s Gemini 2.5 Pro, and Anthropic’s Claude 3.7 Sonnet.
The task was intentionally practical, designed to test real-world utility:
“Create a fun, visually appealing and interactive game that helps newcomers understand hotel Revenue Management and RevPAR optimization.”
(Same prompt supplied to all four models)

Let’s dive deeper into how each performed, based on detailed criteria including cost, processing speed, output quality, and overall usability.
Manus AI: Ambitious But Still Growing
Cost: Manus offers tiered plans, starting at $39/month, with my test consuming about 864 credits, approximately $8.64.
Process: Manus AI shines with its autonomous, multi-agent capabilities, planning and executing tasks independently (see the screenshot below for an example of this task list – I loved watching Manus run through each task and tick it off the list). However, overall execution took around an hour, including initial research and the necessary debugging at the end.
The cool thing about Manus is you can watch a complete replay of the process.
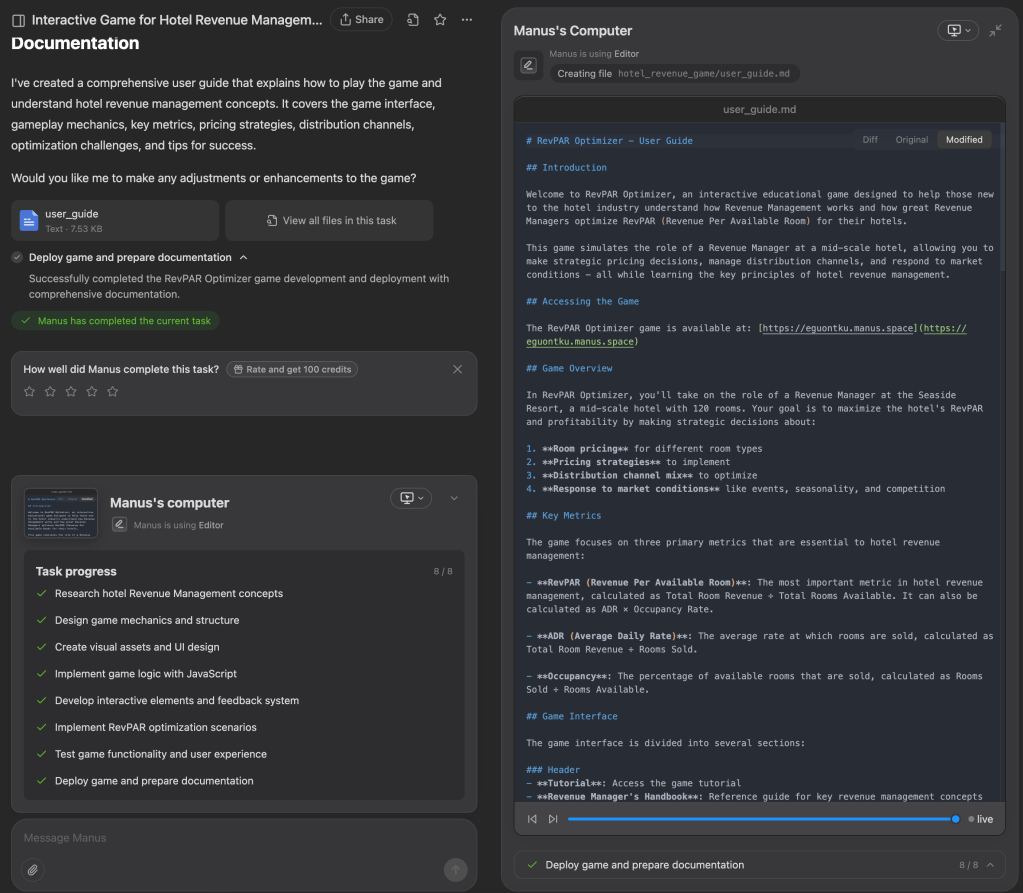
Output Quality: Initially ambitious but incomplete. Despite several iterations, the fully interactive simulation didn’t quite deliver. Manus eventually simplified the game, resulting in a basic but functional version (initial game, simplified version).
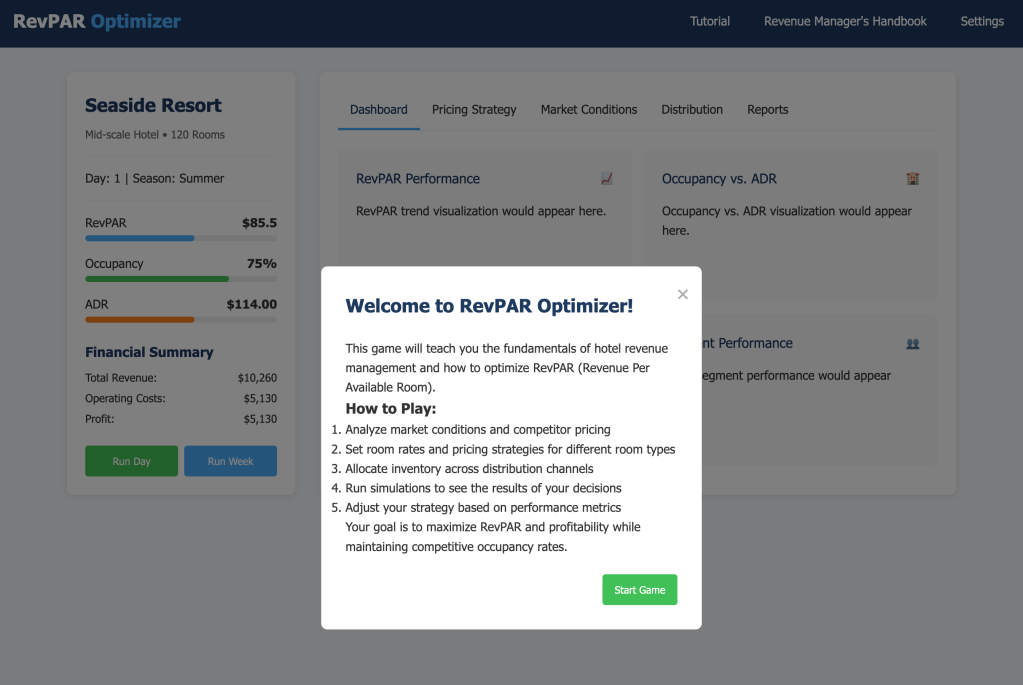
Strengths: Autonomous execution, multi-agent architecture, good transparency.
Weaknesses: Slow processing, occasional instability, limited invite-only accessibility, and potentially high cost.
Google’s Gemini 2.5 Pro: Efficient with Caveats
Cost: Accessible via Google ONE AI Premium for $20/month, minimal additional cost in this test.
Process: Initially hesitant, Gemini needed explicit prompting before creating a simplified but functional “Mini RevPAR Simulator,” completed in under 10 minutes (try here).
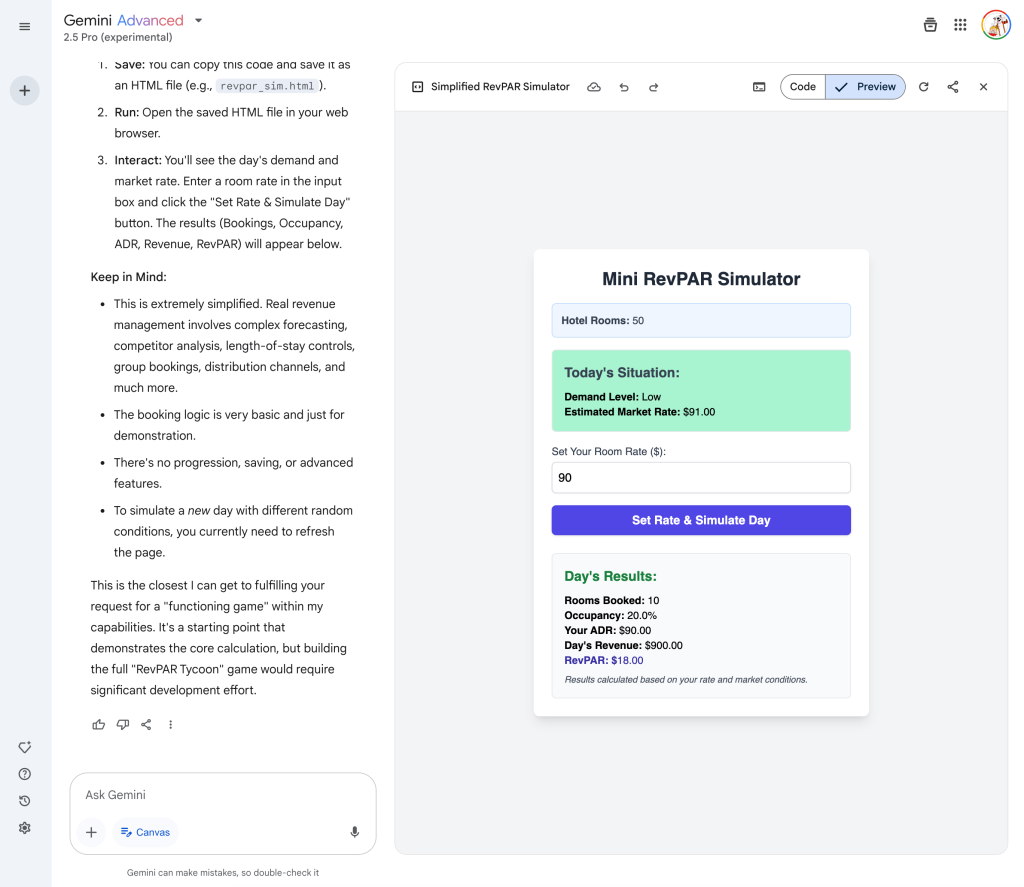
Output Quality: Very simple, practical, and immediate functionality.
Strengths: Outstanding reasoning, massive context handling (1 million tokens), excellent coding abilities.
Weaknesses: Occasional outdated info, coding inconsistencies, verbosity in responses.
OpenAI’s ChatGPT-o1: Robust and Reliable
Cost: Included in the $20/month ChatGPT subscription, negligible additional cost.
Process: ChatGPT quickly conceptualized and executed the game in about 5 minutes, providing HTML code that worked immediately (check code here).
Output Quality: Reliable, effective, though basic.
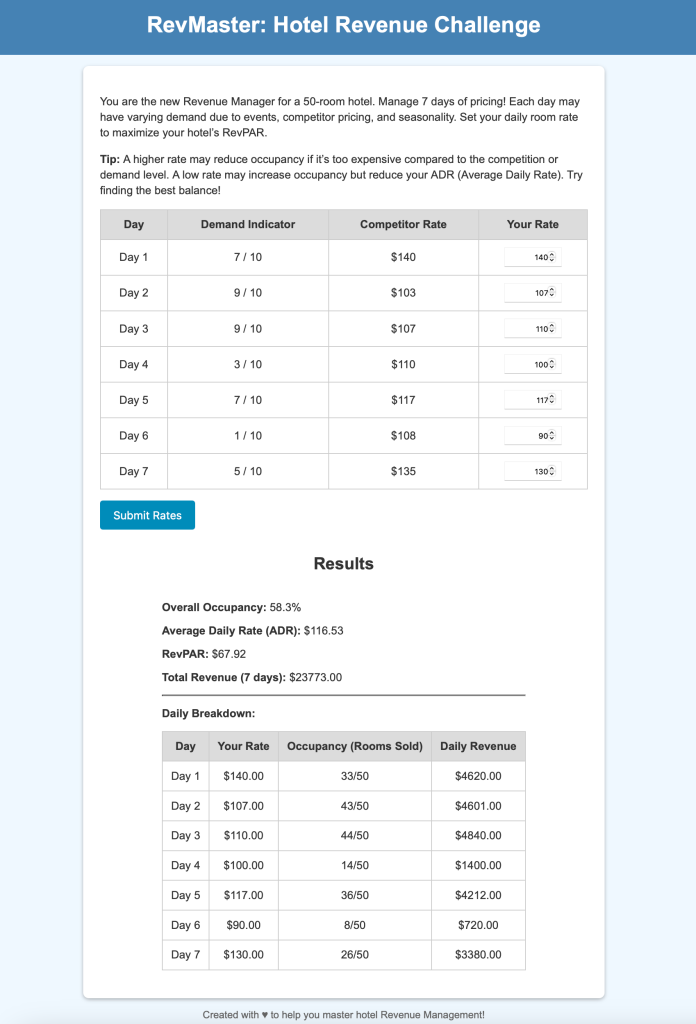
Strengths: Strong reasoning and robust performance in complex tasks.
Weaknesses: Slightly higher cost, slower response time relative to competitors, occasional performance inconsistencies.
Anthropic Claude 3.7 Sonnet: Creative but Temperamental
Cost: Claude Pro is available for $20/month with extended capabilities, making the test’s additional cost negligible.
Process: Claude aggressively pursued an ambitious game but struggled initially due to message length restrictions. After a few attempts and nudges, it simplified the project, eventually producing the best working simulation of the bunch (try it here).
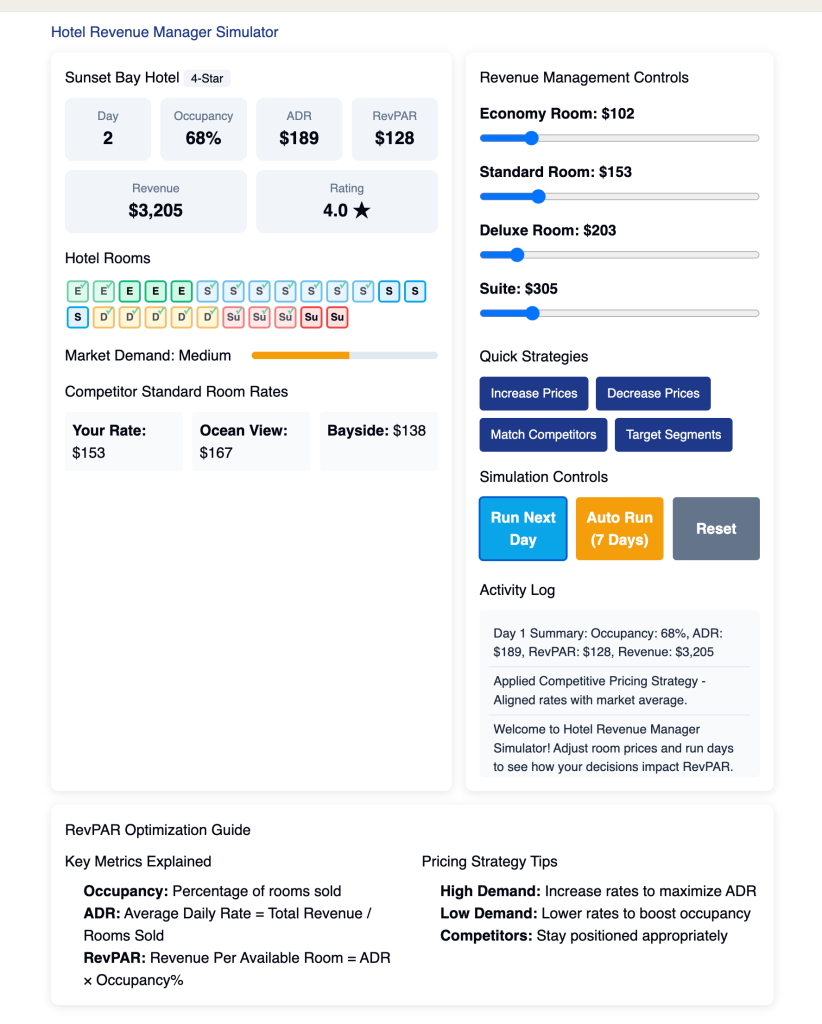
Output Quality: Initially overly complex, but ultimately provided a superior simplified product.
Strengths: Exceptional creativity, strong coding and reasoning abilities.
Weaknesses: Message length limits, intermittent forgetfulness, inconsistencies in long interactions.
Comparative Summary
Here’s a simple table showing how these four tools stack up:
| Feature | Manus AI | Gemini 2.5 Pro | ChatGPT-o1 | Claude 3.7 Sonnet |
|---|---|---|---|---|
| Cost | $$ (med – high) | $ (low) | $ (low) | $ (low) |
| Processing Speed | Slow (~60 min) | Fast (~10 min) | Very fast (~5 min) | Moderate (~15 min) |
| Quality of Output | Ambitious but required simplification | Very simple but functional | Basic, effective | Best simplified product |
| Reasoning & Coding | Good, autonomous | Excellent, large context | Strong, reliable | Exceptional, creative |
| Overall Usability | Promising but limited currently | Efficient with some quirks and lots of nudging required | Robust, practical | Superior in complexity |

Final Thoughts
While Manus AI offers intriguing autonomous capabilities, it’s clear it still needs refinement and lower costs for broader use and adoption. It is a very good sign of things to come, though…this is certainly turning out to be the year of the AI Agent, as predicted. And these tools and agents will only keep getting better.
Claude 3.7 Sonnet, despite its quirks, currently remains my preferred choice for advanced coding and creative tasks. Gemini is excellent for handling extensive contexts and detailed research, and ChatGPT remains the reliable, versatile “Swiss Army knife” of the AI world.
Clearly, if you go with these three models, you’ll have to do more of the research, planning and project management work yourself, but given the cost and capability trade-offs (plus the fact that Manus leans into other models anyway, e.g. Claude for coding), this seems well worth it…for now.
Interested in more detailed testing and real-world comparisons? Let me know your experiences with these models and your go-to tools in the comments below!